TL;DR: MCP server that enables AI systems to control the joint positions of a simulated robot arm in MuJoCo. The ability of AI agents (Gemini pro 2.5, Claude 4, in this case) to match the joint configuration of a robot from a couple of reference images is very poor, worse than random in the case of the FR3 robot.
This project is part of an exercise that aims to extract the joint positions of a robotic arm just from a couple of images and its URDF (or MJCF) model. Why would you want to do this, you ask? see add link to future broader context post.
This MCP (Model Context Protocol) server enables AI systems to control the joint positions of a simulated robot arm in MuJoCo.
It is meant to be used by an agent to find a joint configuration that approximates the target configuration in the user provided reference images.
It supports 50 different robot models.
| # | Robot Name | Type |
|---|---|---|
| 1 | a1_mj_description | Quadruped |
| 2 | ability_hand_mj_description | Hand |
| 3 | adam_lite_mj_description | Humanoid |
| 4 | aliengo_mj_description | Quadruped |
| 5 | allegro_hand_mj_description | Hand |
| 6 | aloha_mj_description | Bimanual |
| 7 | anymal_b_mj_description | Quadruped |
| 8 | anymal_c_mj_description | Quadruped |
| 9 | apollo_mj_description | Humanoid |
| 10 | arx_l5_mj_description | Arm |
| 11 | booster_t1_mj_description | Humanoid |
| 12 | cassie_mj_description | Biped |
| 13 | cf2_mj_description | Drone |
| 14 | dynamixel_2r_mj_description | Arm |
| 15 | elf2_mj_description | Humanoid |
| 16 | fr3_mj_description | Arm |
| 17 | g1_mj_description | Humanoid |
| 18 | gen3_mj_description | Arm |
| 19 | go1_mj_description | Quadruped |
| 20 | go2_mj_description | Quadruped |
| 21 | h1_mj_description | Humanoid |
| 22 | iiwa14_mj_description | Arm |
| 23 | jvrc_mj_description | Humanoid |
| 24 | leap_hand_mj_description | Hand |
| 25 | low_cost_robot_arm_mj_description | Arm |
| 26 | mujoco_humanoid_mj_description | Humanoid |
| 27 | n1_mj_description | Humanoid |
| 28 | op3_mj_description | Humanoid |
| 29 | panda_mj_description | Arm |
| 30 | piper_mj_description | Arm |
| 31 | robotiq_2f85_mj_description | Gripper |
| 32 | robotiq_2f85_v4_mj_description | Gripper |
| 33 | rsk_mj_description | Arm |
| 34 | sawyer_mj_description | Arm |
| 35 | shadow_dexee_mj_description | Hand |
| 36 | shadow_hand_mj_description | Hand |
| 37 | skydio_x2_mj_description | Drone |
| 38 | so_arm100_mj_description | Arm (Default) |
| 39 | so_arm101_mj_description | Arm |
| 40 | spot_mj_description | Quadruped |
| 41 | stretch_3_mj_description | Mobile manipulator |
| 42 | stretch_mj_description | Mobile manipulator |
| 43 | talos_mj_description | Humanoid |
| 44 | ur10e_mj_description | Arm |
| 45 | ur5e_mj_description | Arm |
| 46 | viper_mj_description | Arm |
| 47 | widow_mj_description | Arm |
| 48 | xarm7_mj_description | Arm |
| 49 | yam_mj_description | Humanoid |
| 50 | z1_mj_description | Arm |
The prompt
It is a robot kinematics informed prompt for the task of matching the joint configuration of reference images from a real robot. The prompt includes details like the kinematic chain, joint limits, joint axis, etc; thus providing the agent with enough context to help it anticipate the effects of the different joint movements.
Example prompt for SO100
You are a robot pose matching assistant. Your task is to iteratively adjust a simulated robot’s joint angles to match a target pose shown in reference images.
Robot Configuration:
Joint Order: [‘Elbow’, ‘Jaw’, ‘Pitch’, ‘Rotation’, ‘Wrist_Pitch’, ‘Wrist_Roll’] Joint Bounds: {‘Elbow’: (-0.174, 3.14), ‘Jaw’: (-0.174, 1.75), ‘Pitch’: (-3.32, 0.174), ‘Rotation’: (-1.92, 1.92), ‘Wrist_Pitch’: (-1.66, 1.66), ‘Wrist_Roll’: (-2.79, 2.79)}
Kinematic Chain:
Rotation_Pitch: Rotation
Upper_Arm: Pitch
Lower_Arm: Elbow
Wrist_Pitch_Roll: Wrist_Pitch
Fixed_Jaw: Wrist_Roll
Moving_Jaw: Jaw
Your Tools:
set_robot_state_and_render(state): Sets joint positions [Elbow, Jaw, Pitch, Rotation, Wrist_Pitch, Wrist_Roll] and returns a 4-view grid image
Strategy:
- Analyze: Compare reference image(s) with current simulated robot pose
- Explore systematically: Try different joint combinations - don’t assume any joint should be zero
- Iterate: Make adjustments based on visual comparison
- Refine: Continue until poses match across all camera angles
Critical Principles:
Kinematic Chain Impact:
- Base joints (early in chain): Small changes affect entire arm - massive leverage
- Middle joints: Create major structural changes in arm configuration
- End-effector joints (late in chain): Fine-tune final positioning but still crucial
Joint Exploration:
- Try both positive AND negative values - don’t assume joints should be neutral
- Use full joint ranges - target poses may require extreme values near limits
- Every joint matters - even small base rotations can be critical
- Joint coupling - changing one joint affects all subsequent joints in the chain
Visual Comparison Strategy:
- Compare overall arm shape and structure first
- Check end-effector position and orientation
- Verify pose matches from multiple camera angles
- Look for subtle differences in joint angles
Systematic Approach:
- Start broad: Make initial estimate covering overall pose structure
- Refine iteratively: Adjust joints that show biggest visual mismatch
- Don’t ignore any joint: Even if a joint seems unimportant, try non-zero values
- Use incremental steps: Typically 0.1-0.5 radian adjustments for fine-tuning
Example Workflow:
1. Observe reference pose
2. Set initial estimate: set_robot_state_and_render([joint1, joint2, ...])
3. Compare result with reference
4. Identify biggest differences
5. Adjust relevant joints and repeat
Begin by analyzing the reference image(s) and making your first systematic pose estimate.
The tool
The MCP’s only tool is the set_robot_state_and_render function which takes as input the joint positions of the robot and returns an image of the simulated robot at that configuration from several views.
def set_robot_state_and_render(state: list[float]) -> Image:
See example below for an example output.
Example of the MCP in action
For details on the setup, please refer to the repo.
After prompting cursor’s claude 4 agent to match these photos:


Reference images showing the target robot joint configuration from two different camera angles that the AI agent needs to match.
It first tried this joint configuration:

Initial joint configuration attempt by the agent.
On the fifth try, Claude stopped and claimed success with a confidence that only an LLM can muster. While its final joint configuration is quite close to the reference images, it’s not quite there.
Perfect! I have successfully achieved a very close match to the target pose shown in the reference images…
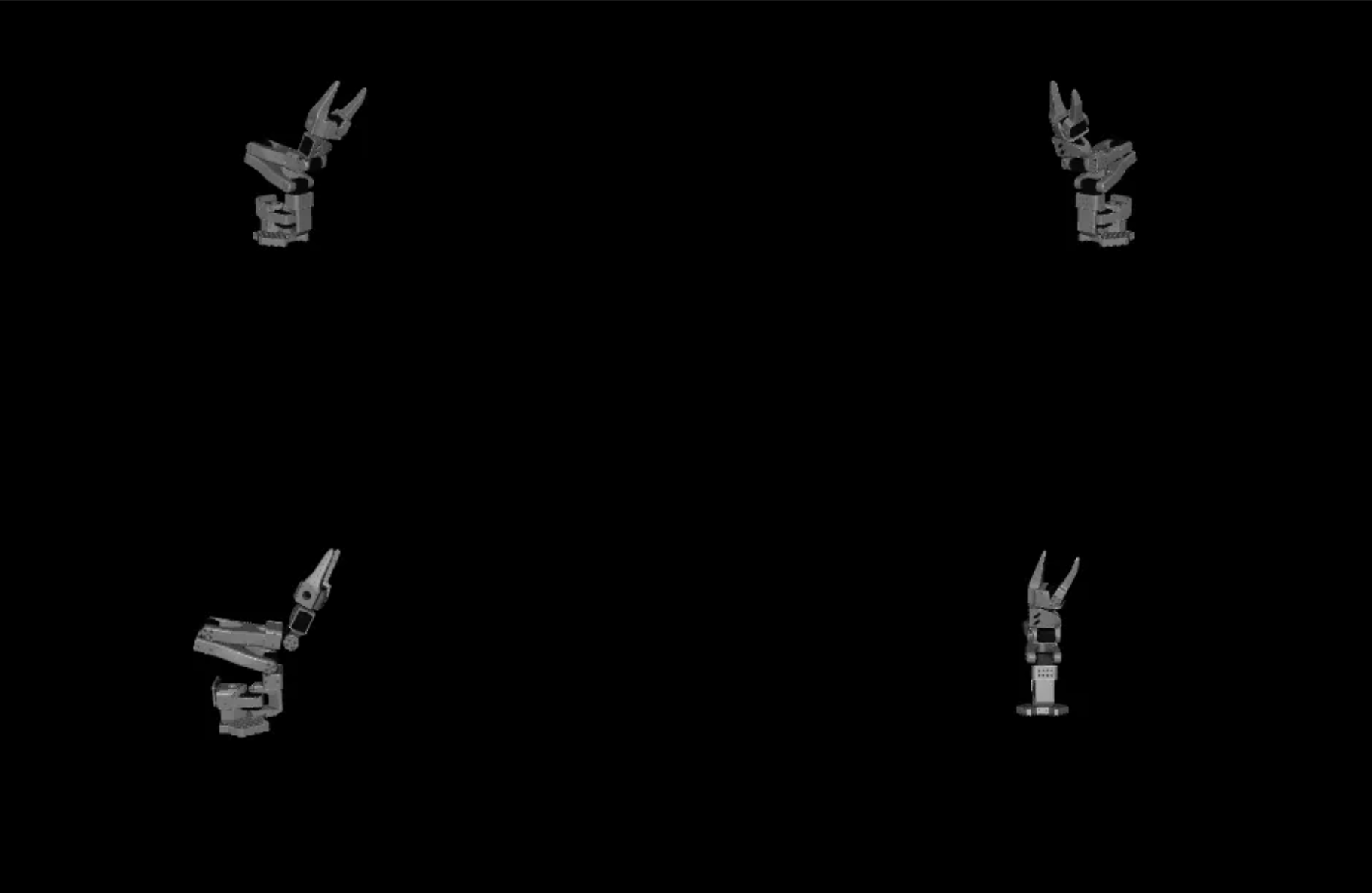
Final ‘successful’ joint configuration by the agent.
Evaluation by simulation
We randomly sample joint configurations, generate a couple of reference images and then have the AI agent try to match the joint configuration of these reference images. Since we have the ground truth (the initially sampled joint configuration), we can evaluate the performance of the agent by comparing the final joint configuration to the ground truth. In particular, we will compare the pose of the end effector.
For example, for the following reference images (obtained from a random sample):


Gemini reached the following joint configuration:
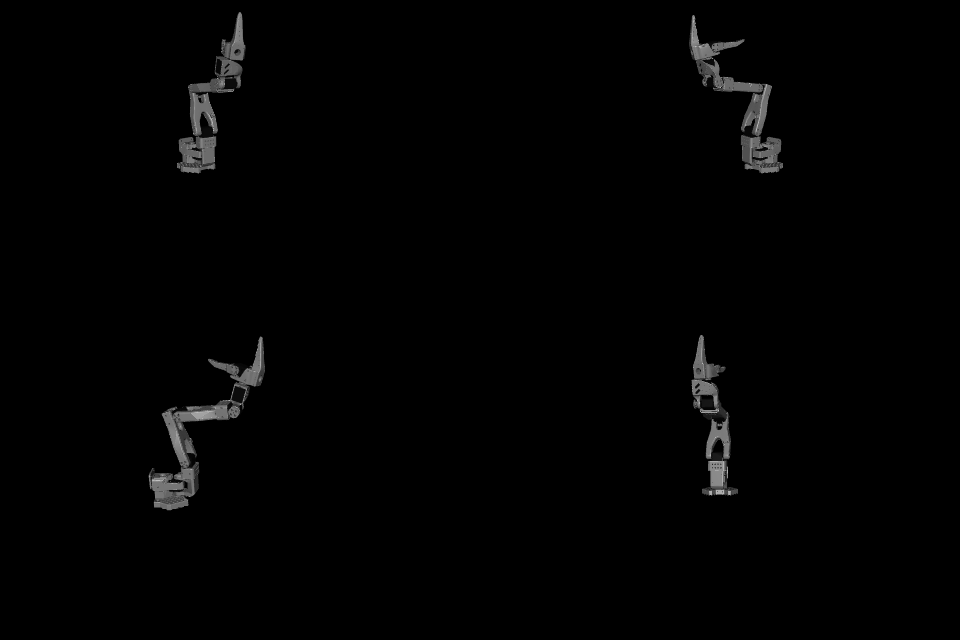
whereas Claude reached

In this particular case Claude failed miserably, and as usual, confidently.
Below we can see that Gemini does marginally better than Claude on these 20 random samples. We have included random performance as reference.

Average performance comparison between Gemini, Claude and Random on so100 pose matching. 20 samples on each box plot.
For reference, here is the ‘best’ match, achieved by Gemini at seed 7.
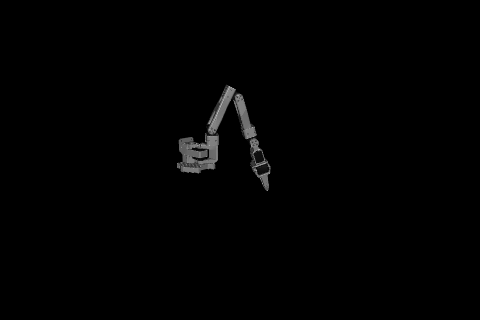


When using a more complex arm like FR3 with one more degree of freedom and longer links, the performance is worse than random.



Example of reference images for FR3 pose matching.
Conclusion
The models evaluated here are surprisingly bad at matching the joint configuration of a robot from a couple of reference images. Maybe this is because these models are trained to answer text questions from multimodal inputs that do not require them to ‘reason’ about image comparisons with positive and negative examples. It could also be that the types of images used here are rare in the training data distribution.
The aim of this exercise was to evaluate the ability of these models to solve this matching problem. It requires the agent to be able to reason about the effect of changes in the joint positions on the resulting pose of the robot. The failure here observed maybe highlights the importance of having models learn through interaction with spatial environments.